Microservices
Table of content
Principles
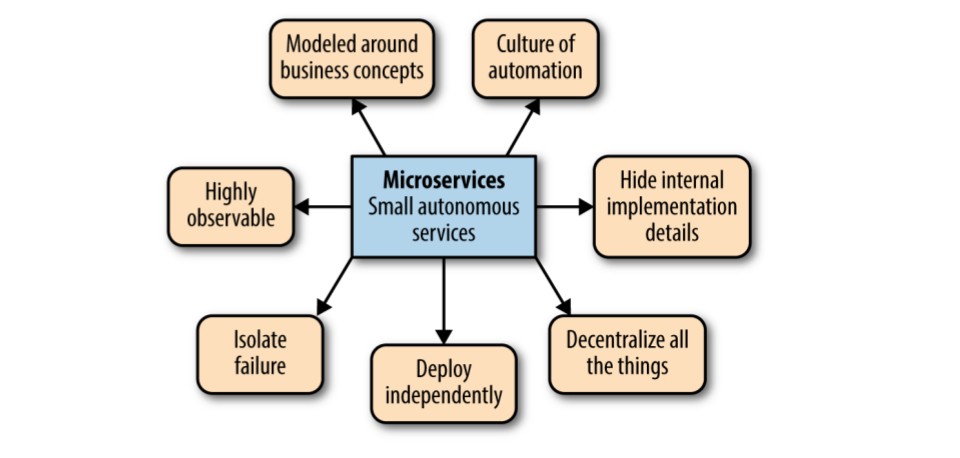
Architecture
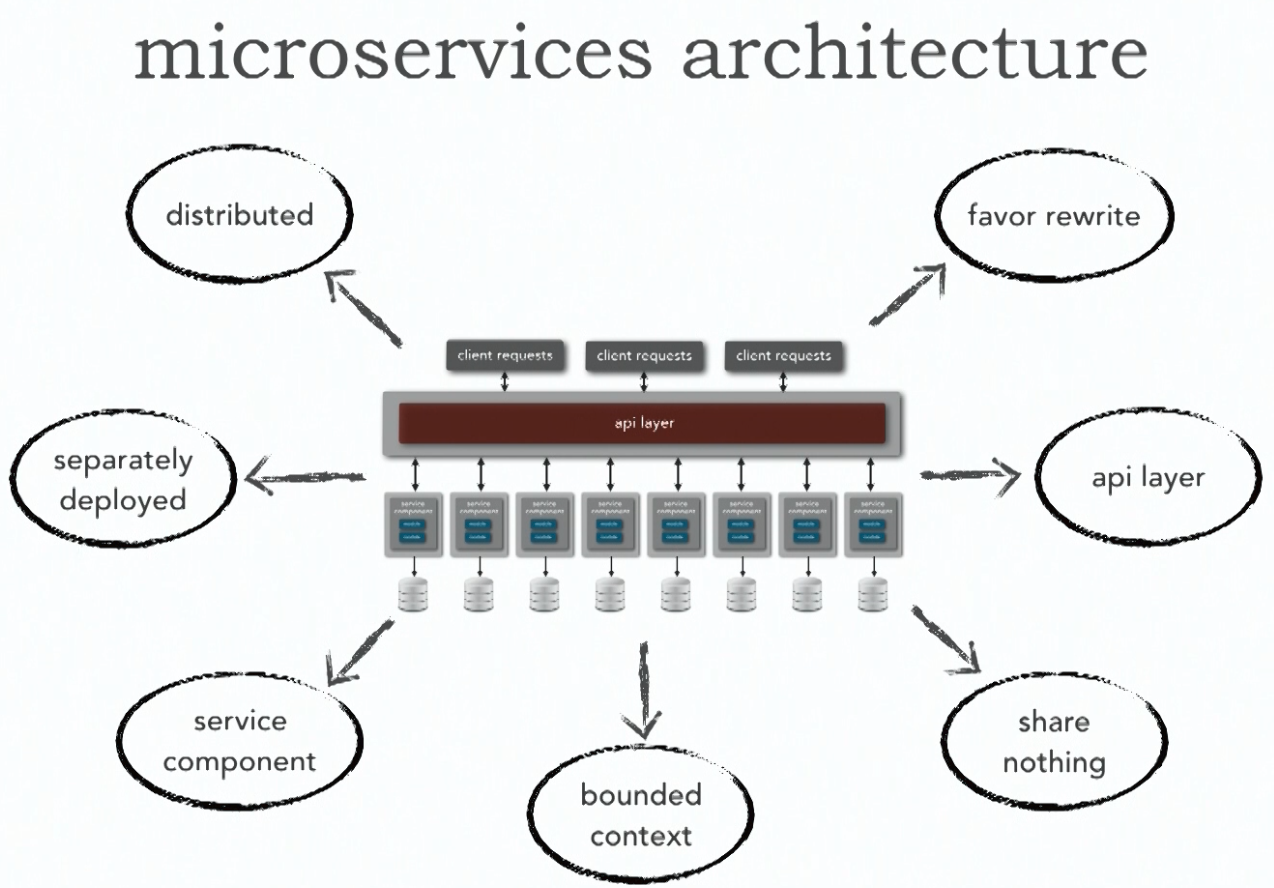
- Service component - is a portion or a building block of an application, which does one specific function. It could contains multiple classes or modules.
- Infrastructure services - logging, error handling, security, auditing
- Functional services - perform some source of buisness function
- API layer allows us to route some part of a traffic to new version and everything else to old one.
- Favor rewrite over maintenance - when we have microservice it easy to rewrite them than to maintain them.
Common
- The goal is create fully isolated service. Which could and should be deployed independenly.
- Do not start with microservices. Because getting bounded context wrong it’s very expensive. So it’s better to wait until thigs become stable
- Retry all requests
- Create topic for error messages
- All event handlers should be idempotent. GET and PUT requests also should be idempotent.
- If you use message queue you should handle the capability for messages to arrive in different order.
API
- Use correct HTTP status codes
- Use correct verbs for HTTP requests
- Use one of the well-known style guide (paypal)
- Use Hypermedia AS the Engine of Application State to reduce coupling. It means send hyperlinks of next actions to a client.Pass reference to the resource in message, not the resource itself. Because by the time message is handled resource my have changed.
- Send with API only necessary fields, by doing this we can change our inner models more easyly
- Use HTTP 202 response code, indicating that the request was accepted but has not yet been processed
- Handle versioning of end points. Doing this we can release a new version of service A
v2, but we should support v1. Then if we have service B which use some of the API of service A, we don’t have to release new version of B, because B still can use version v1.
Bounded Context
- We should split bounded context according to a buissness goals, not according to a data models.
- Share only necessay fields of shared models
Monolith partitioning
- Design your partitioning in the way, which allows parallel development of new features.
- Partitioning strategies:
- Patition by noun, e.g. Catalog Service
- Partition by verb, e.g. Checkout UI
- Partition by subdomain
- Single Responsibility Principle
- Unix utilities - do one focussed thing well
Migration from monolith
- Identify bounded contexts
- Move bounded contexts into separate modules
- Remove unnecessary cross-modules interactions (e.g. if warehouse for some reasone use finance department module)
- Put database associated code into separate modules
- Split database schemas and reduce joins between different bounded contexts
- Choose the most appropriate part (easy to split, need a lot of changes in the feature, necessety to change framework e.t.c) of separation and split it from the monolith
- Start with a place where mistakes cost less
Deployment
- Use only necessary configuration for every service
- Test docker images not standalone code
- Use dedicated system for providing configuration
- Use blue\green deployment
- Use “canary releasing” - when we deploy two version of service and send some amount of traffic on it. We could use some endpoint proxy before any of our microservice to route traffic through it and decide how much of a traffic goes into new version.
- Pass configuration only throw
ENV variables
Tests
- Split all your tests the following categories:
- Unit Tests - test a couple of lines of code. Implemented by stubbing other services dependencies. Runs with every commit.
- Integration tests - check that our stubs (mochs) are correct. Assert all our external dependencies behaviour
- Consumer Driven tests - service tests expectations of every of its consumer
- End-to-End Tests - tests a service in real environment
- Performance tests - should have some criteria to fit, e.g. less than 2 seconds response with 200 concurent users. Should be collected with tests and inside production as well.
- Decrease as possible the running time of tests.
- Fix non-deterministic tests. Eradicating Non-Determinism in Tests
- We should have few amount of end-to-end tests, which covers base “user journeys”. The best case when we don’t need end-to-end tests at all.
- Check Mountebank - it allows to stub http services
Monitoring
- Health check for whole system
- Health check for every server
- Log aggregation
- Monitor downstream communications
- Use correlation ID in logs (to visualize sequential processes)
- Create failure metrics for all of you monitoring parametrs
- Handle and remove unused features
- Implement monitoring of different messages
Scaling
- Prioritize and handle the main cross-functional requirements.
- Response time/latency - how long should various operations take with fixed number of concurrent connections/users.
- Availability - can you expect a service to be down.
- Durability of data - can we lose some data?
- Notice all fallacies of distributed computing
- Do not try to make network reliable, it’s imposible. Focus on recover capability is much better.
- Have the capability to degrade functionality in case when one microservice is broken. We need to ask yourself: “What happens if this microservice is down?”
- Monitor and react (circuit breaker) on a slow services. To not allow them to break the whole system.
- There are two ways of autoscaling:
- predictive - when we have a load metrics and we can use them to scale up\down in predefined time periods
- reactive - when we react on load in runtime
Documentation:
- Use something like grabber to describe system
- Use human registry
Articles
- 12 factored apps
- 12 factored apps addition
- IntegrationContractTest
- SelfInitializingFake
- Eradicating Non-Determinism in Tests
Books
- REST in Practice
- Catastrophic Failover
- Enterprise Integration Patterns
- Refactoring Databases
- Growing Object-Oriented Software, Guided by Tests
- Release It
- Continious Delivery
- Kubernetes: Up and Running
- Agile Testing