notes
Resilience Engineering
All software will fail, but good software fails well
- Definitions
- Safety
- Philosophy
- Improving Reliability
- Stability
- Anti-Patterns
- Patterns
- Failure Types
- Practices
Definitions
- Resilience - a system is resilient if it can adjust its functioning prior to, during, or following events (changes, disturbances, and opportunities), and thereby sustain required operations under both expected and unexpected conditions.
Safety
- Safety - it the system quality that is necessary and sufficient to ensure that the number of events that can be harmful to workers, the public, or the environment is acceptably low.
- Safety 1:
- absence of incidents;
- people and their activities are considered as threat to safety;
- safety activity is centered around creating barriers and removing causes.
- Safety 2:
- errors are routing part of any complex system;
- there is no a clear division between system working and being broken;
- people create safety by their adaptability.
Philosophy
- Reliability is the most important feature.
- Users, not monitoring decide reliability.
- Well engineered software could get you up to the three nines (not more!)
- There are two types of work on improving reliability
- reactive - well trained incident response
- proactive - removing bottlenecks, automating processes and isolating failure.
- There is always tension between reliability and new features. The more features you release the less reliable you become.
- Error budget - the amount of time that you could be unreliable, but still maintain SLO.
- once the error budget is less than 0, you should stop releasing new features and focus on reliability.
- by having this concept we could decrease the tension between Devs and Ops.
Improving Reliability
- Minimal time to recovery consist of:
- time to discover
- time to resolution
-
It’s also very important to consider the “impact” of the issue.
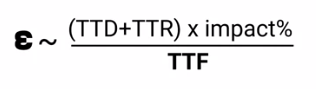
- To improve reliability we could do:
- increase time to failure
- reduce the amount of technical debt
- improve test coverage
- standardize infrastructure
- blameless portmortems
- reduce time to discovery
- alerting
- monitoring
- reduce time to recovery
- self-healing
- monitoring - to help gather the information
- improve logging - for going deeper into details
- improve automation - automating tasks like failover
- playbooks
- save release and rollback systems
- reduce impact
- improve canary analysis
- engineering service to work in partial failure case
- increase time to failure
Stability
A stable system keeps processing transactions, even when transient impulses, persisstent stresses or component failures disrupt normal processing.
Anti-Patterns
Integration Points
- Every integration point will eventually fail in some way, and you need to be prepared for that failure.
- Be ready, that every dependency could be slow to reply, do not reply at all or reply with error.
- Defense:
- Circuit Breaker
- Timeouts
- Decoupling Middleware
- Handshaking
Chain Reaction
- Failure of one server in the pool causes the failure of others.
- There are two sources of chain reaction:
- increased load forced one server in the pool to fail, which increased load on other servers and as a result the next one failed as well.
- resources leak (e.g. memory) in the application could be the reason of server failure, as a result of decreased capacity other servers will go into resource exhaustion state more quickly and the crack will propagate.
- Defense:
- Autoscaling
- Bulkhead
Cascading Failure
- When the failure of one component causes the failure of dependent components.
- Defense:
- Make sure that your service stays up, when one or many dependencies go down
- Pay Close attention on resources pool (e.g. connection pool, thread pool)
- Circuit Breaker
- Timeouts
Patterns
Circuit Breaker
Failure Types
- Recent changes - some new changes introduced a bug.
- Dependency - one of the critical dependencies failed.
- Capacity - server receive more requests than it can handle.
- Requests flow - users use some unexpected workflow which causes the issue.
Resilience in Microservices world.
- Fail quickly and safely
- the scope of failure should collapse completely;
- nothing outside the scope of failure should be impacted (limit blast radius).
- Post-mortems are fundamental ways to understand how your system really works.
- Use circuit breakers
- treat all your downstream services as attackers.
- Measure all the things
- you can’t understand or improve what you can’t measure
- Have a failure budget.
- expect that any of your upstream dependencies can be broken / slow / stuck forever
- expect that any of your downstream dependencies can bombard you with requests
- Instrumentation and observability have no equals.
Practices
- Use only minimal amount of required data - get nice to have data in additional requests and do not block main functionality in case of failure of nice to have services.
- Retry - retry idempotent requests with backoff, jitter and max_retries.
- Timeout calls to external APIs. To not exhaust connections in case of slow \ irresponsible dependency.
- Rate limit clients - to avoid one incorrect client breaking all the customers.
- Finish transactions from failed nodes - e.g. a node started transaction and failed. We should finish such transactions on healthy nodes.
- Show cached data - cache responses from external dependencies and show them in case of failure. Stale data is better than no data at all.
- Communicate with users that you expirience issues and working on fix