notes
SLI, SLO, SLA
Definitions
- Service Level Indicator (SLI) - the quantitative measurement of user happines
- Service Level Objective (SLO) - the threshold on SLI when users are happy. Should be adjusted over time. internal promise to meet customers objectives. Should be stronger than SLA, because usually customers are affected much earlier than the SLA breach.
-
Service Level Agreement (SLA) - promise to customers, if this promise is failed there are financial (or other) consequences.
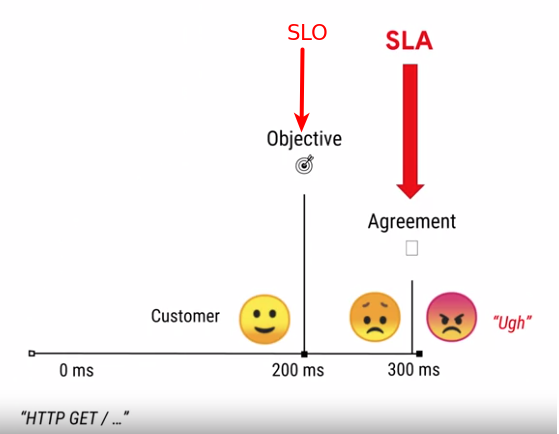
- Error budget - defined as 100% minus the goal for that objective. For example, if there have been 1,000,000 requests to the HTTP server in the previous four weeks, the HTTP availability error budget is 5%
(100%–95%) of 1,000,000 = 50,000 errors
Specification vs Implementation
- SLI Specification - what are you going to measure
- SLI Implementation - how are you going to measure it.
- There could be multiple implementations of the same specification
SLI Specification
How good SLI looks like
- It should be measurable and meningfull by user
- It should be quantifiable
- It should be close to user expirience (users do not care if your database is down or if the load balancer is overloaded, from their perspective the website is down or slow)
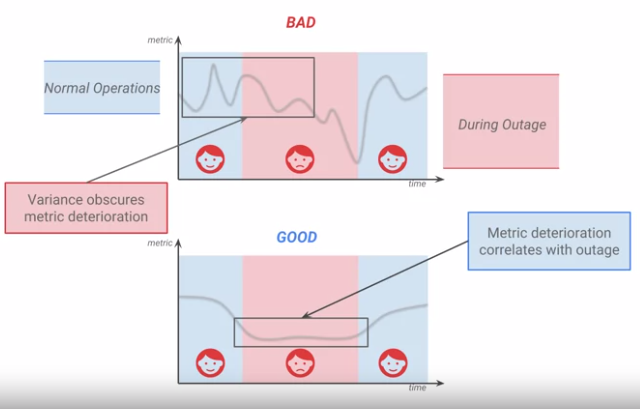
- It should be stable without a big variance
Request / response SLI
- Availability - the proportion of valid requests served successfully
- Latency - the proportion of valid requests served faster than a threshold. Should be set on the long tail. For example 99% of the requests should be served within 100ms. But it’s always worth to consider other percentiles like (75%, 90%, 95%).
- Quality - the proportion of valid requests served without degrading quality. For example in case of an outage you could serve stale requests from cache. In this case, you still fullfill latency and availability SLI, but you work with degraded quality.
Data Processing SLI
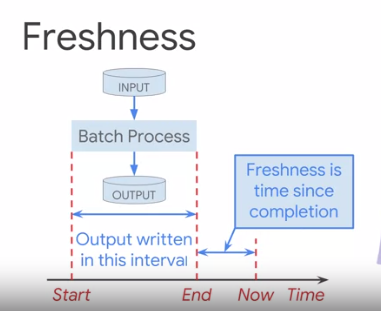
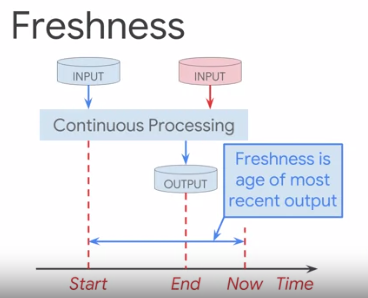
- Freshness - the proportion of valid data updated more recently than a threshold.
-
for batch processing
-
for stream processing
-
- Correctness - the proportion of valid data producing correct output. The measurement of correctness should be independent from the code calculating data, otherwise in case when the result is incorrect we will still count it as correct one.
- Coverage - the proportion of valid data processed successfully (similar to availability for request/response).
- Throughput - the proportion of time where the data processing rate is faster than a threshold (similar to latency for request/response). Easy to explain in bytes per second, the system should expose this metric.
Storage SLI
- Availability
- Latency
- Durability
SLI Implementation
Request/Response Sources of data
- Application server logs
- Load balancer monitoring
- Black-box monitoring
- Client-side instrumentation
Pipeline processing source of data
- Queries from database.
- it could be required to store some additional information in DB to get the SLI for data processing apps
Setting SLOs
- Steps
- Decide who are the users of your application
- Choose an SLI specification for the menu - high-level descriptions of a dimension of reliability that we would like to measure about our service, ideally taking the form “the proportion of valid events that were good”
- Define SLI Implementations - concrete definitions of what the events are, what makes them valid for inclusion into the SLI, what makes them good, and how/where they are measured
- Walk through the user journey and look for coverage gaps.
- Set aspirational SLO targets based on business needs.
- Achievable targets - represent past performance. It’s good to start from historical data when you first set your SLO.
- Aspirational targets - represent business needs. When you set your SLO based on historical data you can not be sure that customers are happy with it (but anyway it’s a good start). So once you set historical SLO work with your businees to set Aspirational SLOs. Keep in mind the faster you want to build - the more expensive it is.
- Coninually improve your SLO until then good enough for user happinest.
- Users happinest depends on past expirience. If you performed extremely well, than degraded performance a little bit => user will be unhappy.
Managing Complexity
- It’s best to have 1-3 SLI for each user journey.
- Not all metrics make good SLIs.
- More SLIs result in higher cognitive load.
- More SLIs lower signal-to-noise ratio.
- Priorotize only journey that have significant impart on user expirience.
- Usually we have much more metrics than SLI
- SLIs tell us that something went wrong
- Metrics tell us what exactly went wrong
- It is usefull to devide thresholds up to 3 buckets:
- background processing (the highest latency treshold, e.g. 5s)
- write response (e.g. 1.5s because users are use to have writes slover than read)
- interactive response (~0.4s)
Documenting SLO
- Every SLO should contain the following:
- Why the threshold is where it is
- Why the SLIs are appropriate for measuring the SLO.
- Identify monitoring data deliberately excluded from SLIs
- Keep SLOs documentation in version control
- ideally next to the monitoring configurations, so that everything is in one place